Introduction
If you find yourself considering web crawling and web scraping as interchangeable terms, you’re in the right spot.
It’s essential to clear up this misconception, as web crawling and web scraping hold distinct roles in the digital realm.
In this article, we’ll delve into the true nature of these practices, their respective applications, and most importantly, we’ll uncover the distinctions that set them apart.
By the end, you’ll have a clear understanding of the unique roles that web crawling and web scraping play in the digital world.

Understanding Web Crawling
The activity of web crawling encompasses the thorough exploration of content within a web page. Commonly referred to as “bots,” “crawlers,” or “spiders,” these digital agents meticulously traverse each web page, carefully examining URLs, hyperlinks, meta tags, and HTML text in order to extract various fragments of data. The collected information is then methodically organized and archived.
This process can be compared to mapping a complex network within the Internet, where indexing robots systematically traverse websites to ensure comprehensive coverage. These robots keep a record of their explorations, preventing repeated visits to the same sites. This dynamic method of web exploration holds paramount importance by fueling search engines and data repositories, thereby simplifying the quest for information within the vastness of the web.
Understanding Web Scraping
Automated data retrieval from publicly accessible web pages is referred to as web scraping. This technique employs specialized software known as web scrapers, which are designed to focus on particular datasets, such as product details or prices.
The extracted data is organized into convenient and downloadable formats like Excel spreadsheets, CSV, HTML, JSON, or XML files.
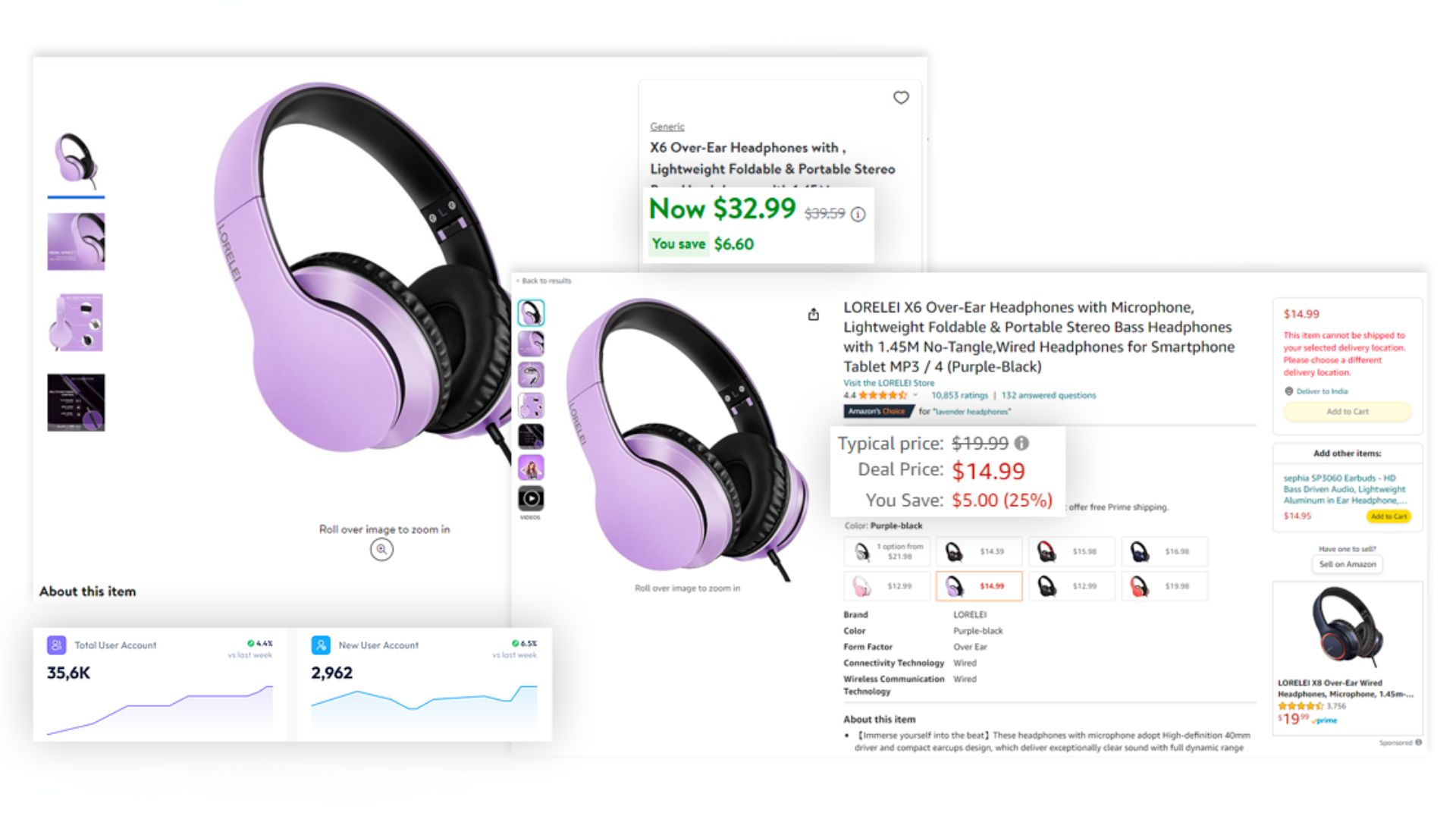
These collected datasets find utility in diverse applications, including comparison, validation, or tailored analysis.
The automated approach not only expedites the data collection process but also enhances precision, outperforming the conventional manual collection method.
This streamlined methodology proves invaluable across various industries, enabling swift and accurate decision-making.
Incorporating Web Crawling and Web Scraping : Practical Applications
Web crawling
Web crawlers find their most prominent utility within search engines, where they play a pivotal role. Google, Bing, Yahoo, Yandex, as well as significant online aggregators, harness these automated bots extensively to maintain the precision of their search results. In an era characterized by a continuous influx of information onto the internet, these bots remain tirelessly active, diligently traversing web pages and updating their indices to ensure up-to-date search outcomes.

Furthermore, beyond the realm of search engines, web crawling and scraping have found application in various domains. E-commerce platforms employ them to monitor and analyze competitors’ product offerings and pricing strategies.
Businesses leverage these techniques to gather market intelligence and sentiment analysis from social media and online forums. Academic researchers harness web scraping to collect vast datasets for studies, and content aggregators curate diverse information from numerous sources, enhancing user experiences.
Web scraping
Web scraping serves a multitude of purposes, finding applications across various domains. From scholarly investigations to business-centric endeavors, its potential is vast.
In academic circles, web scraping stands as a means to amass both quantitative and qualitative data, enriching research across diverse fields. Notably, it plays a pivotal role in the retail, empowering enterprises through competitor analysis and market insights. Automated scraping extracts critical information like inventory specifics, pricing fluctuations, reviews, and emerging trends, all contributing to informed decision-making.
The versatility of web scraping transforms it into an instrument for data acquisition, fostering robust analysis and sound decision-making.

Benefits of Web Crawling and Web Scraping
Web crawling and web scraping serve distinct yet interconnected roles in the data-driven research. Often employed in tandem, these techniques offer a synergistic approach to gathering valuable information.
Advantages of Web Crawling :
- Unveiling the Complete Picture : Crawling empowers researchers by enabling the indexing of every page within the designated source. This meticulous process ensures that no valuable information escapes the scrutiny of keen analysts.
- Ensuring Timely Updates : Up-to-date data is maintained through web crawling, ensuring that emerging competitors and information sources are not overlooked and are instead incorporated into subsequent analyses.
- Ensuring Content Excellence : Leveraging a web crawler proves invaluable for evaluating content quality. By automating the assessment, researchers can efficiently gauge the worthiness of information present on the crawled pages.
Advantages of Web Scraping :
- Unparalleled Accuracy : Web scraping delivers information without any human intervention, guaranteeing that the collected data mirrors the source content with 100% fidelity. This accuracy underpins the reliability of subsequent analyses.
- Enhanced Cost Efficiency : The labor-intensive and time-consuming nature of manual data collection makes web scraping an appealing alternative. Outsourcing data collection to a scraper translates to substantial savings in staff hours.
- Precise Targeting : Web scraping offers a finely tuned approach to information extraction. Users can configure scrapers to pinpoint specific data, such as prices, images, or descriptions, conserving time, bandwidth, and financial resources.

Navigating the challenges of Web Crawling and Web Scraping
Both web crawling and web scraping share set of challenges that practitioners must navigate.
Addressing preventative policies
A significant hurdle that both web crawling and web scraping encounter is the presence of anti-crawling and anti-scraping policies deployed by numerous domains.
These protective measures can impede data gathering, leading to potential delays or, in extreme cases, an IP address blockade.
To circumvent such obstacles, businesses can employ proxies. These proxies serve as intermediaries, substituting the actual user IP address with an alternate one drawn from a diverse pool of IPs.
Beyond enhancing data harvesting efficiency, this approach safeguards user privacy.
Managing capacity concerns
The processes of web crawling, web scraping, and subsequent data analysis demand substantial labor and time investments. Simultaneously, the hunger for information-driven insights is an ever-growing appetite.
The incorporation of automated solutions into these operations emerges as a strategic choice for conserving valuable business resources.
In the face of these shared challenges, a proactive stance involving proxy utilization and automation adoption can empower businesses to navigate the complexities of web crawling and scraping more effectively.
Conclusion
Crawling and scraping constitute distinct processes that, when combined, facilitate enhanced automation and yield improved outcomes.
This harmonious approach proves especially invaluable for industries reliant on data-driven decision-making, such as the Retail sector.
By seamlessly acquiring and harnessing the required information, this methodology empowers businesses to make well-informed choices.
In catering specifically to the retail, our cutting-edge solution,, Optimix Pricing Analytics (XPA), ensures data collection both online (crawling websites) and physically in-store using smartphones (capturing photos of product labels and utilizing AI for EAN price recognition and labeling).


